Data-applicaties bieden eindgebruikers snel en interactief toegang tot informatie. Deze apps analyseren grootschalige datasets op de achtergrond met moderne Data Science technologieën, waardoor ze informatie direct kunnen voorzien van context en gebruikers in staat stellen om onmiddellijk actie te ondernemen op basis van deze inzichten.
Maar hoe zorg je ervoor dat een data-applicatie altijd relevant blijft?
De levenscyclus van Data-applicaties
Een data-applicatie is niet af zodra deze in productie wordt genomen, maar blijft voortdurend in beweging. Dit komt doordat de kwaliteit van de onderliggende data in de applicatie voortdurend verandert. Er komt meer data bij en de wereld evolueert, wat leidt tot veranderingen in de data. Hierdoor moet je er voortdurend voor zorgen dat de data-applicatie de juiste en relevante inzichten blijft bieden voor het nemen van beslissingen. Dit principe van voortdurende verandering staat bekend als 'drift':
De veranderingen in de data die worden gebruikt om voorspellingen te doen met een model, worden vergeleken met de historische data die is gebruikt om het model te trainen.
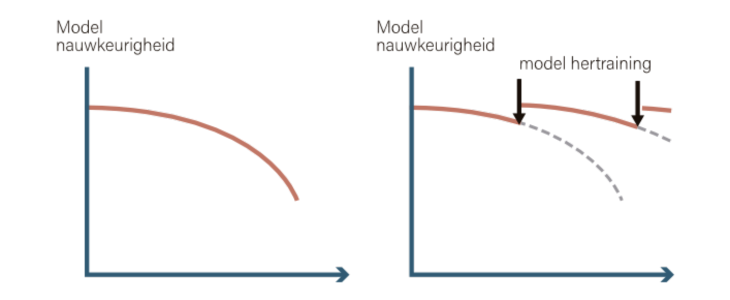
In de onderstaande figuur is dit weergegeven. De nauwkeurigheid van het model neemt af in de loop van de tijd. Meestal is de oorzaak hiervan drift en dit geeft aanleiding om het model op nieuwe data te trainen.
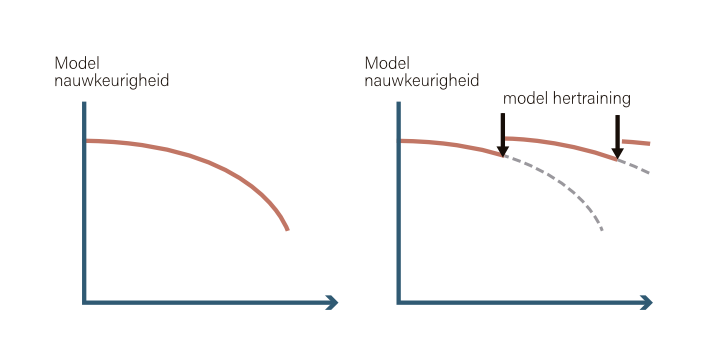 Figuur 1: Model nauwkeurigheid verloop in de tijd
Figuur 1: Model nauwkeurigheid verloop in de tijd
Er worden twee soorten drift onderscheiden, data drift en concept drift.
Data drift
De data die wordt gebruikt in de voorspelling wijkt significant af dan waarop het model is getraind. Bijvoorbeeld de voorspelling van stroomopbrengst van een zonnepaneel. Stel dat het model alleen is getraind met data uit de zomer. In de winter zijn de inputvariabelen anders, bijvoorbeeld doordat sneeuwval op het zonnepaneel zorgt voor een verkleining van het paneeloppervlak of de afname van zonnestraling in de winter. Hier kan het model hier niet goed mee omgaan en zal daardoor geen accurate voorspellingen van de stroomopbrengst in de winter geven.
Concept drift
De relatie tussen de te voorspellen waarde en de input variabelen verandert, terwijl de input nog gelijk blijft. Dit wordt concept drift of ook wel model drift genoemd. Bijvoorbeeld huizenprijzen. Een model getraind met prijzen van een aantal jaar geleden, werkt nu niet meer goed terwijl de eigenschappen (inputvariabelen) van de huizen niet veel veranderd zijn.
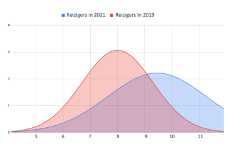
Of in het voorbeeld hiernaast bij het voorspellen van het aantal reizigers gedurende de dag voor corona (2019) of tijdens corona (2021) is duidelijk een afwijking te zien in het patroon. De mensen hebben hun reisgedrag substantieel aangepast. De piek van 2019 om 8 uur ’s ochtends, ligt in 2021 rond 9:30 en is veel lager en meer uitgesmeerd. Dit terwijl de input variabele ‘tijdstip’ niet veranderd is.
Daarnaast moet je de kwaliteit van de data in continue in de gaten houden. Want de uitkomst van een data-applicatie is zo goed als de kwaliteit van de input data. De belangrijkste aspecten om mee rekening te houden zijn gaten in de data door fouten, te laat of niet beschikbaar gekomen input data.
Beide aspecten van drift en datakwaliteit zijn onderdeel van de in het zogenaamde Observability bouwblok dat wordt beschreven in het blog Data-Applicaties Ontleed: Ontdek de Essentiële Bouwstenen voor Succes.
Full Orbit & Data-Applicaties
Om succesvol en effectief over te gaan naar een digitale en innovatieve organisatie is er meer nodig dan alleen het ontwikkelen en gebruik van data-applicaties. Bij Full Orbit helpen we organisaties om de digitale transformatie te starten met de juiste kennis, strategie en oplossingen. Dit doen we door middel van een stapsgewijze aanpak die past bij het tempo van de specifieke organisatie.
Meer weten?