Data-applicaties, ook wel bekend als analytische of data-gedreven toepassingen, onderscheiden zich door hun ondersteuning bij besluitvorming. Ze bieden gebruikers direct contextuele informatie voor snelle acties door grootschalige datasets te analyseren met moderne Data Science technologieën, waardoor eindgebruikers snel en interactief toegang krijgen tot informatie.
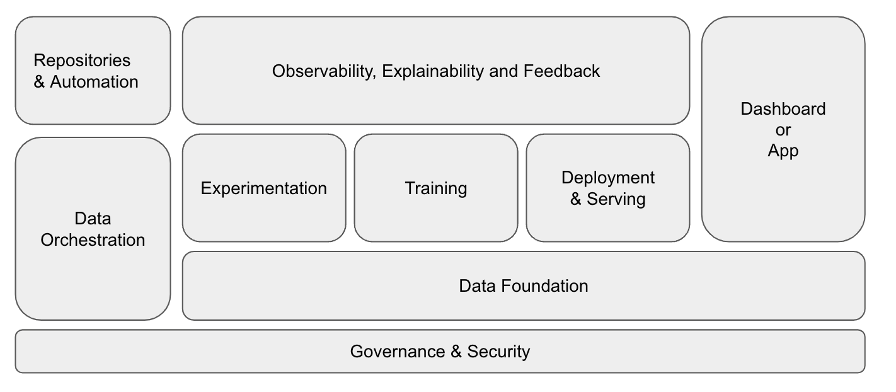
De functionele bouwblokken van een data-applicatie
Wat heb je allemaal nodig voor de ontwikkeling en beheer van een data-applicatie?
Heel simpel gezegd bestaat een data-applicatie uit drie lagen: de datalaag, de intelligentielaag die samen de backend vormen en de gebruikerslaag die de frontend vormt.
Voor de intelligentielaag wordt steeds meer gebruik gemaakt van Machine Learning (ML) en kunstmatige intelligentie (AI). Dit stelt aanvullende eisen aan de benodigde bouwblokken. De onderstaande figuur schetst deze bouwblokken in haar samenhang:
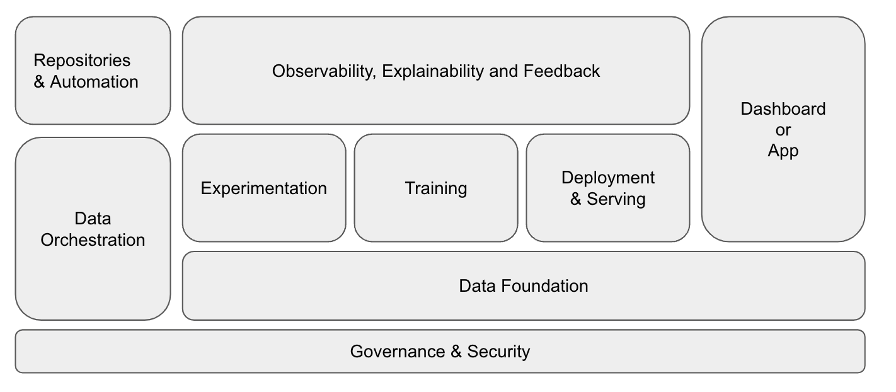
Figuur 1: De functionele bouwstenen van een data-applicatie
1. Repositories & Automation
Alle onderdelen van data-applicaties zijn software en worden vaak door een of meerdere teams ontwikkeld en beheerd. Vanuit de DevOps best practices voor softwareontwikkeling is versiebeheer van essentieel belang. Hierbij sla je alle broncode op in een repository. Om snelheid en kwaliteit te garanderen is automatisering van het software voortbrengingsproces cruciaal. Hierbij ligt de focus op ‘continuous integration’ en ‘continuous delivery’ ook wel CI/CD genoemd. Deze bouwsteen bevat alle tools en practices die nodig zijn om op een effectieve en kwalitatieve manier data-applicaties te ontwikkelen.
2. Governance & Security
DataOps past de hierboven beschreven DevOps-principes toe in de wereld van data-analyse en zorgt voor de levenscyclus van hoogwaardige datasets. Deze datasets zijn cruciaal voor data-applicaties. Om kwalitatieve datasets te creëren en hoogwaardig te houden zijn de volgende practices van belang:
- Structureren en integreren: Vaak bestaat een dataset uit meerdere samengestelde, getransformeerde, geaggregeerde basis datasets of brondata.
- Meta data: dit bevordert de vindbaarheid, het gebruik en de governance van de dataset.
- Data kwaliteit: Fouten, gaten of afwijkingen in de data kunnen bij data-applicaties leiden tot foute beslissingen.
- Data governance: Wie mag en heeft toegang tot welke dataset en voldoet de dataset aan de geldende wet- en regelgeving.
3. Data foundation
De data foundation is de bouwsteen waarin alle data is opslagen. Vaak bevinden gegevens zich in meerdere datastores (databases, objectstores, featurestores, etc). Het gaat in deze bouwsteen niet om brondata, maar om alle data die nodig is om alle data-applicaties en analytics te voeden. Naast de daadwerkelijke data maakt ook metadata deel uit van de data foundation. De metadata bevatten waardevolle informatie over de data en worden gebruikt voor zoeken, vinden, versiebeheer, en voor de governance- en security bouwsteen.
4. Data orchestration
De gegevens die nodig zijn voor data-applicaties moeten vaak worden omgezet van brongegevens naar inzichten. De data orkestratie bouwsteen zorgt voor al deze benodigde processen. Dit betekent het verkrijgen van de ‘ruwe’ gegevens uit de bron en het verrijken ervan. Bij verrijken moet je denken aan opschonen, transformeren, integreren, filteren en aggregeren. Het doel van de verrijking kan meerledig zijn. Bijvoorbeeld het bij elkaar brengen van verschillende gegevens die inzichten opleveren, zoals een kaart met verschillende kaartlagen. Een ander doel is het voeden van een AI-model. Vaak worden de verschillende dataverwerkings stappen achterelkaar gekoppeld. Dit noemen we een datastroom of data pijpleiding. Al deze verwerkingsprocessen hebben een volgordelijkheid en tijdigheid, vandaar dat dit georkestreerd moet worden. Alles wat nodig is om de datastromen te ontwikkelen en beheren is onderdeel van deze bouwsteen.
5. Experimentation
Veel data-applicaties hebben een AI/ML component in de vorm van een AI-model. De modelontwikkeling heeft een experimenteel en iteratief karakter. De eerste stappen in de ontwikkelingslevenscyclus zijn het verkennen van gegevens met behulp van statistische methoden, het testen van hypothesen en het uitproberen van verschillende algoritmes. De experimenteer bouwsteen wordt hoofdzakelijk gebruikt door data scientists. De uitkomsten van verschillende experimenten moeten worden vastgelegd voor latere referentie en evaluatie om het beste kandidaat model te selecteren. Er zijn verschillende tools beschikbaar om dit proces te ondersteunen. Het resultaat van de Experimentation function is een set aan features en een geselecteerd algoritme.
6. Training
Met het resultaat van de experimentation bouwsteen moet het AI-model worden getraind op een geselecteerde dataset. Dit is het doel van de training bouwsteen. De geselecteerde, gevalideerde en getrainde modellen worden bewaard in een model repository, zodat de Deployment & Serving bouwsteen weet welke modellen er beschikbaar zijn voor gebruik.
In de loop van de tijd verandert de wereld en dat geldt ook voor de gegevens die voor het model worden gebruikt. Dit resulteert in een afname van de nauwkeurigheid en betrouwbaarheid van het model. Bijvoorbeeld zoals door de coronapandemie het reisgedrag van mensen veranderde, zullen modellen die getraind waren met data voor de coronapandemie geen goede uitkomsten geven voor voorspellen van reisgedrag, Om het model in de loop van de tijd accuraat te houden, is daarom hertraining vereist. Dit proces kan handmatig of automatisch worden geactiveerd, vaak op basis van statistieken verkregen uit het Observability bouwblok.
7. Deployment & Serving
Zodra een model is getraind en gevalideerd, is het klaar om te worden gebruikt in de intelligentie laag van een data-applicatie. De Deployment & Serving bouwsteen zorgt ervoor de dat de AI-modellen als functie beschikbaar komen (‘deployment’) en via een API aanroepbaar zijn (‘serving’) op het productieplatform. De aanroep van een model kan op een aantal manieren plaatsvinden. De twee meest voorkomende manieren van aanroep zijn:
- Moment in de tijd: elke ochtend worden omzetvoorspellingen voor alle producten voor de dag gegenereerd;
- Door gegevens/gebeurtenissen: een gebruiker selecteert een product en het model geeft een aanbeveling van andere relevante producten op de e-commerce pagina.
8. Dashboard / App
Gebruikers hebben interactie met de data-applicaties zowel professioneel als privé. Bijvoorbeeld het voorstellen van de beste verkoopacties, signalen van fraude, aanbevelingen, enz. De front-end van een data-applicatie is meestal een dashboard of app.
9. Observability, Explainability & Feedback
Data-applicaties zijn net zo goed als de data waarmee ze worden gevoed, zowel voor training van modellen of inzichten die worden geleverd. Om de kwaliteit van de output te garanderen, moeten zowel de gebruikers, ontwikkelaars en beheerders continue worden geïnformeerd over de kwaliteit van de uitkomsten.
Dit is het doel van de Observability, Explainability & Feedback bouwblok:
- Observability: Aan elk type stakeholder worden de gewenste inzichten geleverd gegevenskwaliteit, modelprestaties en systeemprestaties te bewaken.
- Explainability: De rationale van een ML-model wordt steeds belangrijker naarmate meer beslissingen op ML-modellen zijn gebaseerd. Dit is het gebied van de uitlegbaarheid, bijvoorbeeld op basis van welke variabelen de verwachtte omzet is gebaseerd.
- Feedback: Een toevoeging om modellen steeds verder te verbeteren is het voorzien van een feedbackfunctie. Zakelijke gebruikers kunnen het systeem feedback geven over de uitkomsten van het model.
In de data-applicatie hieronder zijn alle drie de onderdelen aanwezig.
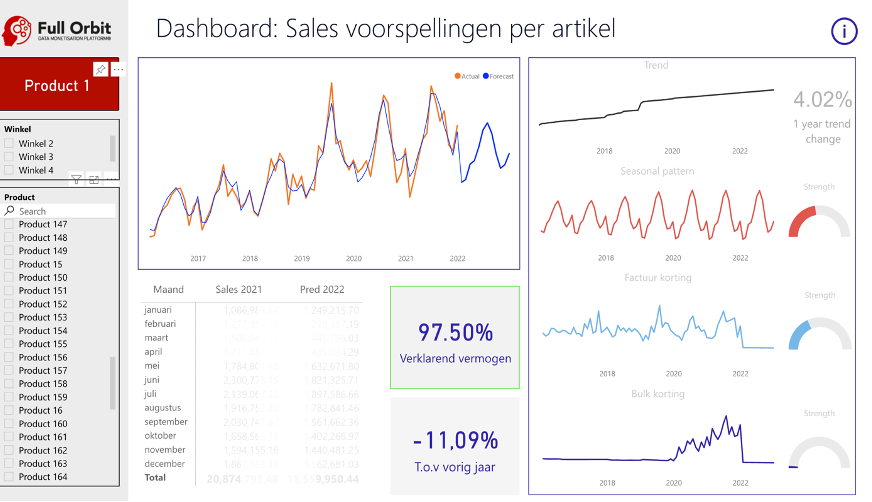
Figuur 2: Data-applicatie sales forecast
Full Orbit & Data-Applicaties
Om succesvol en effectief over te gaan naar een digitale en innovatieve organisatie is er meer nodig dan alleen het ontwikkelen en gebruik van data-applicaties. Bij Full Orbit helpen we organisaties om de digitale transformatie te starten met de juiste kennis, strategie en oplossingen. Dit doen we door middel van een stapsgewijze aanpak die past bij het tempo van de specifieke organisatie.
Meer weten?
Wil je meer weten over het ontwikkelen van Data-Applicaties? Download dan de whitepaper "Data-applicaties: Succesvol realiseren, beheersen en groeien"