

Auto Oplaadnetwerk Planning met Genetisch Algoritme
Genetische algoritmes worden in veel domeinen toegepast, zoals engineering, financiën en biologie. Het genetische algoritme is een generiek model en kan toegepast worden op verschillende...

Door de informatie-explosie die de laatste decennia heeft plaatsgevonden is er een analysekloof ontstaan. Dit betekent dat de productie van gegevens veel sneller is toegenomen dan ons vermogen om het te analyseren.
Daarnaast ontstaat er in een hoge dimensie de vloek van dimensionaliteit. Wanneer je dataset een groot aantal variabelen bevat loop je bijvoorbeeld het risico op overfitting. Dit verschijnsel treedt op wanneer algoritmen in staat zijn de train data perfect te fitten. Hierdoor wordt het voor Machine Learning algoritmen lastig om patronen in de data te ontdekken, zonder dat er enorm veel trainingsdata is.
Door de grote hoeveelheid data die tegenwoordig beschikbaar is, en de bijbehorende nadelen van een hoge dimensie is er een focus ontstaan op het verminderen van het aantal features in de data. Je wilt enkel de relevante variabelen in je dataset houden, en de irrelevante variabelen weglaten. Om dit te realiseren zijn er verschillende feature-selectie methoden ontwikkeld.
Zoals eerder benoemd wil je als Data Scientist enkel de meeste relevante variabelen in je model gebruiken. Feature selectie is het proces van het selecteren van deze variabelen.
Hierdoor zal je model beter presteren en zullen de rekenkosten verlagen. Daarnaast kun je de uitkomsten van het model beter analyseren.
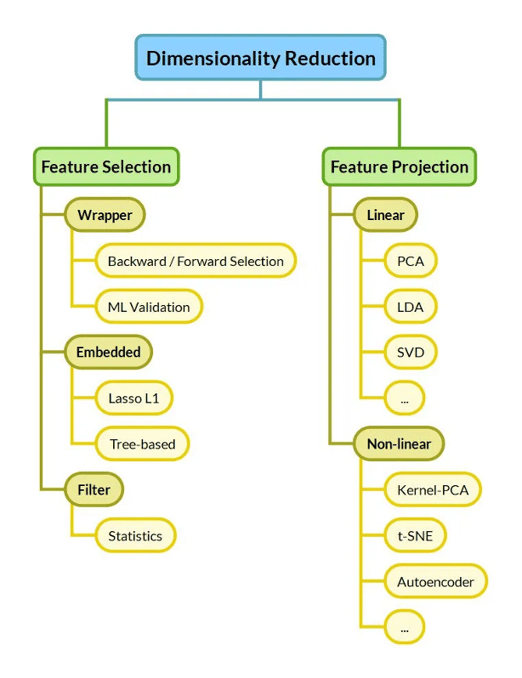
Er bestaan verschillende type feature selectie methoden, die kunnen worden geclassificeerd onder wrapper methoden, filter methoden en embedded methoden. Daarnaast bestaan er feature projectie methoden. Deze hebben ook als doel om de dimensie van de dataset te reduceren, maar doen dit door de oorspronkelijke set variabelen de transformeren naar een lagere dimensie, in plaats van het selecteren van de meest relevante variabelen.
Bij wrapper methoden is het de bedoeling dat je al een algoritme en prestatiemaatstaf hebt gekozen die je wilt gaan gebruiken. Met wrapper methoden test je de prestatie van je model voor alle mogelijke verschillende feature subsets. Vervolgens wordt die feature subset gekozen waarbij de prestatie van het model optimaal is. Er zijn diverste wrapper technieken die verschillen in het samenstellen van de set aan feature subsets die geëvalueerd moeten worden:
Filter methoden gebruiken statistische technieken om het belang van features in de dataset te meten. Voorbeelden van zulke statistische techieken zijn de correlatie met de output variabele, de variantie van de features en de chi-square test. Een voordeel is dat deze methoden rekenkundig snel en goedkoop zijn. Echter, deze statistische technieken worden op individuele features toegepast waardoor geen rekening wordt gehouden met interacties tussen variabelen. Dit laatste is een nadeel van filter methoden.
Embedded methoden beschikken over de voordelen van zowel wrapper als filter methoden. Naast lage rekenkosten houden deze methoden rekening met effecten van feature combinaties. Met behulp van algoritmen worden de meest relevante features uit de data gehaald. Hierbij worden bepaalde criteria gebruikt om te bepalen welke features het meest bijdragen in het trainen van het model. Twee populaire embedded feature selection methoden zijn:
Voor bovengenoemde feature selectie methoden was er meestal een uitkomstvariabele nodig in de dataset. Oftewel, deze methoden zijn geschikt voor supervised learning problemen. Naast supervised learning bestaat er unsupervised learning, waarbij er geen uitkomstvariabele in de data aanwezig is. Denk hierbij bijvoorbeeld aan clustering problemen. Ook binnen de unsupervised learning is een overschot aan features nadelig.
Een alternatief voor unsupervised learning om het aantal variabelen te verminderen is het inzetten van feature projectie methoden, ook wel dimensie reductietechnieken genoemd. In plaats van het zoeken naar de beste variabelen om in je model te behouden, vinden dimension reductietechnieken juist een combinatie van nieuwe variabelen, terwijl ze zo veel mogelijk van de variantie in de originele dataset proberen te behouden. Het transformeert de oorspronkelijke set verklarende variabelen naar een lagere dimensie.
Feature selectie voor unsupervised learning wordt daarom ook wel feature projection genoemd. De twee meest gebruikte projectie methoden zijn Principal Component Analysis (PCA), Linear Discriminant Analysis (LDA).
 Conclusie
ConclusieIn deze blog hebben we verschillende feature selectie methoden beschreven waarmee het aantal dimensies in een dataset gereduceerd kan worden. Afhankelijk van het Data Science probleem en de beschikbare tijd kan met behulp van deze blog een goede keuze gemaakt worden welke feature selectie methode geschikt is voor het specifieke probleem. Voor supervised learning kunnen wrapper, filter en embedded methoden overwogen worden. Gebruik je unsupervised learning? Ga dan voor een feature projectie methode
Wil je meer weten over feature selectie in een Data Science project? Download dan de whitepaper "De 6 basisprincipes van een Data Science Project".

