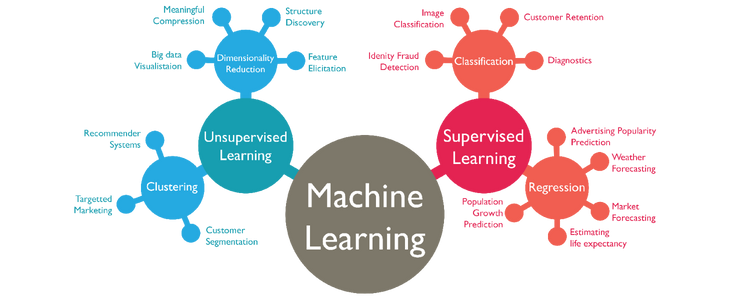
Machine Learning wordt tegenwoordig overal gebruikt. In elke sector probeert van Machine Learning te profiteren. Het onderzoeksgebied Machine Learning is er op gericht om machines te leren cognitieve activiteiten uit te laten voeren, vergelijkbaar met het menselijke brein. Hoewel Machine Learning algoritmen vaak beperkter zijn dan de cognitieve vaardigheden van de gemiddelde mens, zijn ze wel in staat om grote hoeveelheden data snel te verwerken en bruikbare, intelligente inzichten te verkrijgen.
Typen Machine Learning algoritmen
Er zijn diverse Machine Learning algoritmen die verschillen in de manier waarop ze leren. De twee meest voorkomende typen algoritmen zijn supervised en unsupervised learners.
Supervised learning
Bij supervised learning wordt gebruik gemaakt van een gelabelde dataset die zowel de gewenste input als output gevat. Supervised learning kan verder opgedeeld worden in regressie en classificatie. Bij regressie is het doel een continue variabele te voorspellen, zoals het voorspellen van de toekomstige verkopen. Bij classificatie wordt een categorie voorspeld. Denk hierbij bijvoorbeeld aan afbeelding classificatie.
Unsupervised Learning
Unsupervised Machine Learning algoritmen maken voorspellingen op basis van ongelabelde data, waarvan er er geen output bekend is. Unsupervised learning algoritmen kunnen verborgen patronen of bepaalde groeperingen vinden in de data. Dit type Machine Learning kan verder onderverdeeld worden in clustering algoritmen (bijvoorbeeld klantsegmentatie) en dimensie reductie technieken (bijvoorbeeld beeldcompressie)
De top 10 meest gebruikte Machine Learning algoritmen
Onder de bovengenoemde categorieën Machine Learning algoritmen vallen diverse verschillende soorten algoritmen. De 10 populairste Machine Learning algoritmen zijn:
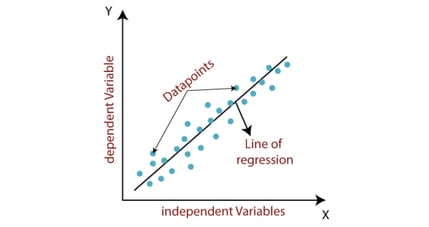
1. Lineaire Regressie
Lineaire regressie is waarschijnlijk het meest bekende regressie algoritme binnen Machine Learning. Het idee van lineaire regressie is om een lijn te vinden die het best de relatie tussen de input variabelen (X) en de output variabele (y) beschrijft, en daarmee de fouten minimaliseert. Denk bijvoorbeeld aan het vinden van de relatie tussen woonoppervlakte en de waarde van een huis. Deze lijn staat bekend als de regressie lijn, en kan worden weergegeven als een lineaire vergelijking
Y = a*X + b
Hier is Y de output variabele, X de input variabelen, a de gewichten van de input variabelen en b een constante. Er worden waarden gevonden voor a en b zodat de fouten tussen het model en de werkelijke waarden worden geminimaliseerd.
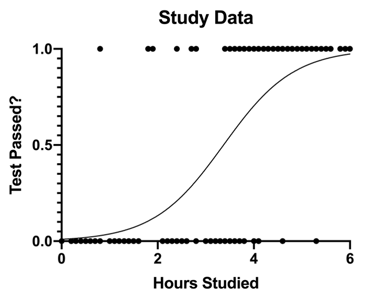
2. Logistic regression
Logistische regressie wordt gebruikt voor het schatten van categorische variabelen en valt daardoor onder classificatie algoritmen. Het schat de waarschijnlijkheid dat een observatie binnen een bepaalde categorie valt. De categorie met de hoogste waarschijnlijkheid is de uiteindelijke voorspelling. Dit wordt gedaan door een logit curve te vinden die de relatie tussen de data het best kan beschrijven. Bijvoorbeeld voor het vinden van de relatie tussen het aantal uren dat iemand heeft gestudeerd en het wel/niet halen van een toets kan logistische regressie toegepast worden.
3. Decision Trees
De Decision tree is een supervised Machine Learning algoritme dat zowel voor regressie als voor classificatieproblemen gebruikt wordt De data wordt hierbij weergegeven in een boomstructuur waarbij elk blad overeen komt met een mogelijke uitkomstvariabele. Onderstaande afbeelding geeft een simpel voorbeeld van een classificatie boom weer voor het voorspellen van de waarde van een huis. Net zoals bij eerder genoemde algoritmen is het doel om de fout tussen de voorspellingen en werkelijkheid te minimaliseren. Daarom wordt de boom op dusdanige manier gemaakt dat de fouten minimaal zijn, en de relatie tussen de in- en output variabelen zo goed mogelijk wordt gerepresenteerd.

4. Random Forest
Een collectief aan decision trees wordt een Random Forest genoemd. Meerdere decision trees worden getraind waarbij elke boom een voorspelling maakt. Echter, per boom wordt slechts één subset van de data gebruikt om de decision tree te creëren. Vervolgens worden de uitkomsten van alle trees samen genomen om één waarde of één meerderheidscategorie als uitkomst te voorspellen. Dit verkleint de variantie van het model ten opzichte van slechts één enkele decision tree.
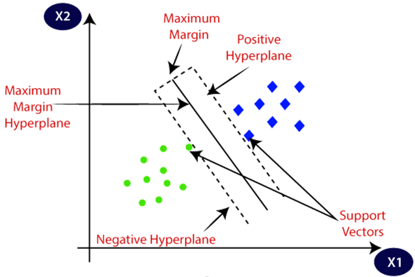
5. SVM
Een support Vector Machine (SVM) kan gebruikt worden voor zowel classificatie als regressie. Echter, SVM's worden vooral gebruikt voor classificatietaken. Het idee van een SVM is dat het een hypervlak vindt die het best een dataset in categorieën kan verdelen, zoals in onderstaande afbeelding is weergegeven. Dit wordt gedaan door een hypervlak te zoeken met de grootst mogelijke marge tussen het hypervlak zelf en de punten in de trainingsdataset. Dit verhoogt namelijk de kans dat de SVM voor nieuwe, ongeziene, datapunten de correcte categorie voorspelt.
Het gebeurt vaak dat er geen duidelijke hypervlak te vinden is, en dat de datapunten niet lineair scheidbaar zijn. In dat geval kan de SVM naar een hogere dimensie worden getild, wat ook wel kernelling wordt genoemd. Het idee van kernelling is dat de data in steeds hogere dimensies worden getild totdat er een hypervlak gevormd kan worden. Onderstaande afbeelding geeft weer hoe een niet-lineair scheidbaar probleem in 2d naar een derde dimensie kan worden gelift om het lineair scheidbaar te maken.
-2.png?width=570&name=Kernel%20(1080%20x%20860%20px)-2.png)
6. KNN
K-nearest neighbours (KNN) kan voor classificatie en regressie problemen worden gebruikt. KNN kan worden vergeleken met het dagelijkse level hoe mensen worden beïnvloed door de mensen om hun heen. KNN wijst namelijk een nieuw, ongezien datapunt een waarde toe op basis van de dichtstbijzijnde datapunten in de training dataset. Hierbij moet de gebruiker van het algoritme aangeven met hoeveel ‘buren’ er rekening gehouden moet worden. Wanneer k op 5 wordt gezet betekend dit dat de 5 punten uit de trainingsdata die het dichtstbij het nieuwe punt liggen worden bekeken. Voor classificatie is de meerderheidsgroep van de 5 punten de voorspelling en voor regressie wordt het gemiddelde van de waarden van de 5 punten genomen als voorspelling.
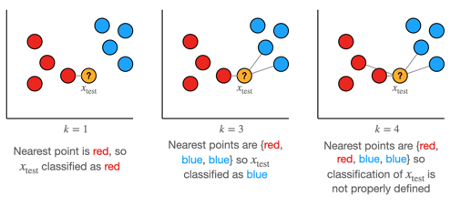 7. K-Means
7. K-Means
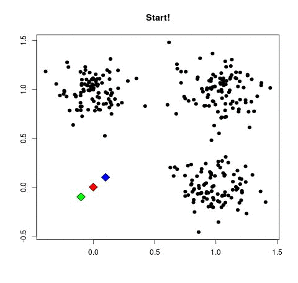
K-means is een clustering algoritme. Het wordt gebruikt om unsupervised Machine Learning problemen op te lossen. Het probeert vergelijkbare datapunten samen te groeperen in de vorm van clusters zodat punten binnen een cluster zo veel mogelijk op elkaar lijken en punten in verschillende clusters zo veel mogelijk van elkaar afwijken. Het aantal cluster, K, wordt bepaald door de gebruiker van het algoritme. Het algoritme kan samengevat worden in de volgende stappen:
1. Kies K random zwaartepunten die de clusters initialiseren
2. Wijs de datapunten toe aan het dichtstbijzijnde cluster zwaartepunt
3. Bereken de nieuwe zwaartepunten van de gevormde clusters
4. Herhaal stap 2 en 3 totdat de clusters niet meer veranderen
Onderstaande figuur visualiseert het k-means algoritme.
8. Naive Bayes
Naive Bayes is een probabilistisch algoritme dat wordt gebruikt voor classificatieproblemen. Naive Bayes is gebaseerd op de theorie van Bayes en maakt gebruik van de meest fundamentele kennis van kanstheorie. Daarbij wordt een naïeve aanname gedaan dat de voorspellers onafhankelijk zijn van elkaar. Ook al voldoet deze aanname in werkelijkheid bijna nooit, toch laat Naive Bayes goede prestaties zien in veel toepassingen. Zo heeft Naive Bayes goede prestatie voor tekst classificatie, ondanks dat hier wordt aangenomen dat de individuele woorden in een zin onafhankelijk zijn van elkaar, wat natuurlijk niet het geval is.
9. Boosting Algoritmen
Boosting is een classificatie algoritme dat iteratief ‘weak learners’ combineert om er een ‘strong learner’ van de te maken. Met een weak learner wordt een algoritme bedoelt dat net iets beter classificeert dan een random classificatie. Een voorbeeld van een weak learner is een decision stump (een decision tree met slechts 1 level). Elke weak learner probeert de zwakheden van zijn voorganger te compenseren. Dit zorgt ervoor dat de combinatie van alle weak learners één sterke voorspelregel creëert. Er bestaan diverse boosting algoritmen die verschillen in hoe ze de weak learners creëren en aggregeren. De vier bekendste boosting algoritmen zijn:
- Adaptive boosting (AdaBoost): Dit algoritme identificeert per weak learner de onjuist geclassificeerde datapunten, en past de gewichten van deze punten aan om meer focus op deze punten te leggen.
- Gradient boosting: In plaats van het veranderen van de gewichten van datapunten, zoals in AdaBoost, traint Gradient boosting de weak learners op de residu fouten van de voorgaande voorspeller, en probeert deze te minimaliseren.
- Extreme gradient boosting (XGBoost): XGBoost is een implementatie van gradient boosting die is ontworpen voor betere rekensnelheid en schaalbaarheid. XGBoost maakt gebruik van meerdere cores op de CPU zodat het trainen parallel kan plaatsvinden.
- Light-GBM: LightGBM is ook andere variant van Gradient Boosting, die lijkt op XGBoost. Echter, Light-GBM voegt twee extra features toe die zorgen voor een nog snellere training tijd en een hogere efficiëntie. Daarbij heeft LightGBM over het algemeen een hogere accuraatheid dan XGBoost.
10. Principal Component Analysis
Principal Component Analysis (PCA) is een van de populairste lineaire dimensie reductie technieken. PCA zet een grote set variabelen om in een kleinere set variabelen die zo veel mogelijk informatie van de grote dataset bevat. Hierdoor kunnen trends, clusters en outliers worden geobserveerd. Daarbij kan deze nieuwe kleinere set variabelen relaties beter weergeven. PCA heeft dus als doel om een grote dataset te visualiseren in 2 of 3 dimensies, zonder dat er een significant verlies van waardevolle informatie plaatsvindt. Daarnaast kan PCA gebruikt worden voor dimensie reductie om de trainingstijd van een Machine Learning-model te verminderen, aangezien het gebruik van minder features zorgt voor een kortere trainingstijd.
Conclusie
Voor elk Data Science probleem moet worden nagegaan welk algoritme het best toepasbaar is. In deze blog hebben we een korte samenvatting gegeven van de meest gebruikte Machine Learning algoritmen. Elke algoritmen heeft zijn voor- en nadelen, en daarom moet er altijd goed overwogen worden welk algoritme het meest geschikt is. Naast de bovengenoemde algoritmen bestaan er natuurlijk nog veel meer Machine Learning algoritmen, en worden er continu nieuwe algoritmen geïntroduceerd die de prestatie van de bestaande algoritmen proberen te verbeteren. Houd daarom ook deze nieuwe ontwikkelingen in de gaten!
Meer weten?
Wil je meer weten over de verschillende typen Machine Learning algoritmen? Download dan de whitepaper "De 6 basisprincipes van een Data Science Project".