

Auto Oplaadnetwerk Planning met Genetisch Algoritme
Genetische algoritmes worden in veel domeinen toegepast, zoals engineering, financiën en biologie. Het genetische algoritme is een generiek model en kan toegepast worden op verschillende...

Data Science maakt gebruik van een combinatie van domeinkennis, codeervaardigheden en statistische expertise om zakelijk problemen op te lossen en waardevolle inzichten te verkrijgen.
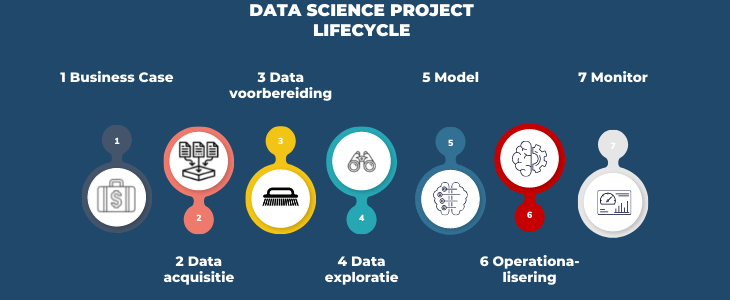
Om tot een goed eindresultaat te kunnen komen dient een Data Science project een aantal vastgestelde fasen te doorlopen welke worden gespecificeerd in het zogenaamde Data Science Lifecycle model. Dit model geeft duidelijke handvatten voor, en inzicht in de binnen het project te verrichten werkzaamheden.
In dit blog bespreek ik de 7 stappen van het Data Science Lifecycle model, en het belang ervan om een daadwerkelijk succesvol Data Science project te kunnen realiseren.
Vaak worden Data Science Projecten niet vanuit een business case gestart, maar op basis van “Zou het niet cool zijn als...?" vragen. De uiteindelijke waarde van een Data Science project hangt echter af van een duidelijke business case. Wat wil je bereiken met het project? Wat is de toegevoegde waarde voor de organisatie en hoe gaat de informatie uit een algoritme uiteindelijk gebruikt worden?
Het ontwikkelen van een AI algoritme vraagt vaak om grote hoeveelheden kwalitatief goede data, omdat de intelligentie gebaseerd wordt op de informatie die in de data aanwezig is.
Hoe kom je aan deze goede data en informatie? Hiervoor is een goede samenwerking met de beoogde Business Users van het model, de IT-afdeling en de Data Engineers noodzakelijk. De IT-afdeling en de Data Engineers hebben de juiste rechten hebben om de data te kunnen ontsluiten. De Business Users kunnen helpen om deze data in de juiste context te plaatsen.
Als je eenmaal over de noodzakelijke gegevens beschikt, ga je over op de datavoorbereidingsfase. Dit gedeelte van het Data Science proces wordt in het Engels vaak aangeduid als “data cleansing” of “data wrangling” en richt zich op het identificeren van de verschillende problemen met betrekking tot datakwaliteit.
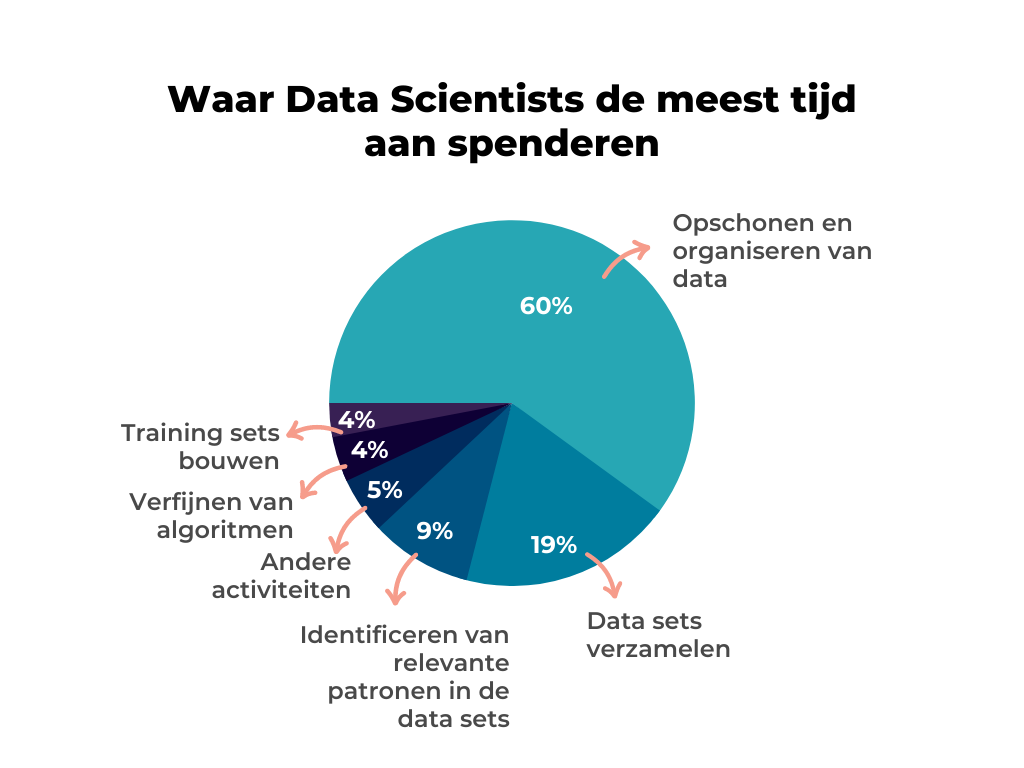
Bijna 80% van een Data Science prokect wordt besteed aan gegevensverzameling en het opschonen en organiseren van data.
Als de relevante data eenmaal gestructureerd is aangeleverd moet deze verder onderzocht worden en gecontroleerd. Verschillende soorten gegevens zoals bijvoorbeeld numerieke data, categorische data, ordinale en nominale data enzovoort moeten op verschillende manieren behandeld worden.
Vervolgens worden beschrijvende statistieken gebruikt om specifieke kenmerken naar boven te halen en significante variabelen te testen.
Tot slot wordt datavisualisatie ingezet in de vorm van bijvoorbeeld cirkeldiagrammen, lijndiagrammen of staafdiagrammen, om patronen en trends in de data te identificeren.
Dit is de kernfase van de Data Science Life cycle waar de “magie” plaatsvindt. Het doel is het maken, uitvoeren en verfijnen van modellen, gebruikmakend van o.a. statistische analyses en Machine Learning technieken, om uit de geprepareerde data zinvolle zakelijke inzichten te kunnen herleiden.
Als de Data Scientists de data eenmaal hebben gemodelleerd, kunnen gebruikers er inzichten uithalen en feedback geven. Zijn de voorspellingen van het model logisch? Missen essentiële variabelen die invloed zouden kunnen hebben? Hebben de gevonden relaties ook een causaal verband?
Hoe nauwkeuriger deze feedback wordt vastgelegd, hoe effectiever de wijzigingen die eventueel in het model moeten worden aangebracht en hoe nauwkeuriger de uiteindelijke resultaten.
We praten veel met de Data Science-teams van bedrijven, en het is opvallend hoe vaak ze zich niet bewust zijn van de kloof tussen een goed Machine Learning-model en een productieklare Machine Learning-applicatie. Dit is een van de redenen waarom, volgens recent onderzoek van Gartner, minder dan de helft van de Machine Learning-modellen volledig is geïmplementeerd.
Dus wat is er nodig om Machine Learning-modellen in productie te nemen?
Omdat in de ontwerpfase nadruk ligt op het snel ontwikkelen van een succesvol model, kan de kwaliteit van de programmeercode nog wel eens te wensen overlaten. In de productiefase wordt deze programmeercode juist erg belangrijk. Daarom wordt deze code in de productiefase vaak opnieuw gestructureerd, waarbij het uiteindelijke model losgemaakt van alle experimenten die zijn gedaan tijdens de ontwerpfase.
Het prototype moet opgenomen worden in de bestaande processen in de organisatie. Belangrijk hierbij zijn het automatiseren van de datastromen, en het opzetten van een infrastructuur voor hosting en beheer. Het model moet beschikbaar zijn voor alle gebruikers en moet kunnen meeschalen met het gebruik ervan.
Een model dat in een productieomgeving draait en gebruikt wordt, moet nog altijd gecontroleerd worden of het goed blijft werken en bruikbaar blijft. Het continu bewaken van het gebruik en de performance van een model, alsmede het automatisch calibreren en eventueel hertrainen van ervan, zijn van essentieel belang.
Wil je meer weten over de waarde die Data Science je bedrijf kan bieden? Download dan de ‘Handleiding voor succesvolle Data Science projecten”. Daarin vertellen we je wat de factoren van een geslaagd Data Science project zijn, en in welke stappen je van een idee tot een goede oplossing komt.

